TDD 与 BUG 的爱恨情仇(卷三),本系列链表头部请戳 A song of TDD and BUG - 前奏曲
副歌不副,FTDD 不 F
可能你在想,不是 A song of TDD and BUG 吗?怎么都到了副歌部分了,还没怎么说 TDD。这个可能就要怪我们民国的大师们把 Chorus 翻译成副歌了,明明是最高潮的部分,翻译成副歌总给人一种莫名其妙的感觉,不过也可能是我乐理不精对大师的翻译没有深刻理解导致的。那吐槽吐完,开始讲正事,之前有给过大家一个强烈但不失友善的警告大家应该还记得吧,不记得的可以去复习一下 A song of TDD and BUG - 主歌。那会我说过适合自己的才是最好的,俗话说的好,规则就是用来打破的,只要我们了解了 TDD 的真谛,就可以把它改造成最适合自己的开发模式,我把这些 TDD 的变种们称为 FTDD。那何谓 FTDD,这个多出来的 F 代表什么?其实就是 Fu..,不好意思,是 Fake,也就是“伪 TDD”。那为什么说 FTDD 不 F 呢?因为这个“伪”并不是真正意义上的伪,而是结合了自己对 TDD 的理解和实践的产物,也可以理解为 F(it)TDD,也就是合适的 TDD。
走进 TDD
在 A song of TDD and BUG - 前奏曲 中我已经提到过 TDD 的基本步骤,不知道你还记得不,我再重复一遍:
- 写一个失败的单元测试
- 完善代码让测试通过
- 重构
- 重复上述步骤到天荒地老
上边的步骤又被叫做 Red-Green-Repeat Cycle, 虽然看起来简简单单几个步骤,但是其实都是有不同的考量的。
首先我们从第一个开始说,看到第一个的时候不知道你怎么想,我的第一反应是这个步骤太蠢了吧,我还没写代码,为啥先要写个失败的单元测试。但如果我们结合单测的编写原则就不难理解了,其中有一条是单测必须是可失败的,所以我们先写一个失败的单测是为了证明它是可失败的。当然这条比较有争议,因为你完全可以写完一部分功能了再写单测,重要的是不要留一个空的单测,这不仅是浪费时间,更重要的是我们在以后很有可能以为自己这部分代码是由单测保证的而耽误了找 Bug。
第二个步骤当然不言自明,我们的目的就是这个。但是这里边还是隐藏着一个前提,就是每次在写一个新的单测之前要先确保之前所有单测都跑通过。这个除了提醒你项目现在状态很好之外,还有一个很重要的作用是保证单测的可重复性。你不是每次只单独跑一个单测,而是没写一个就会把全部单测都跑一遍。
其实在第二个步骤中还有一个隐性的作用,就是保证单测的高效性(这个是编写单测的第三个原则),由于需要频繁的跑单测,你就必须把单测写的很节省时间(100 ms 阈值)。
第三个是重构,需要注意的是,如果重构对于整个单元的对外接口有改动的话,你需要同时修改单元测试以保持它们之间的同步。不过如果你不修改接口的话有很大可能单测会是你重构的保护神。
第四个步骤很好理解,就是重复上述步骤直到没有新的需求,我用天荒地老应该不过分吧。
细测不是胡测
单测不是万能的,但没有单测是万万不能的。
不好意思我“借鉴”了三国杀里陆逊的台词(读书人的事怎么能叫抄呢),但我觉得用这个能精准表达我的意思。从上边的部分我们可以看出 TDD 非常看重单测覆盖率,有一种单测能解决一切的感觉。不得不承认,如果我们能覆盖所有分支并模拟所有可能出现的情况,理论上应该可以实现完全覆盖。但是现实很骨感,我们必须要考虑成本因素。
这部分的标题是“借用”了某表演艺术家的名言。这里的“细测”指的是高效率的单测,而“胡测”指的是盲目的给什么都做单测,盲目的追求100%的测试覆盖率成本很高,总体收益也不大。那我们可以猜测一下 Rainstorm 中哪些单测是高效的,哪些是低效的?估计你已经猜出来,网络代码的测试是高效的,而 ViewModel 中输出的单测是低效的。那具体是什么原因呢?我们对比一下这两种代码的不同,网络代码逻辑相对复杂,分支比较多,在真正输出之前,输入经过了好几次转手;而 ViewModel 的输出仅仅是把 Model 中的数据转换了一下格式输出,而这个转格式的工作也是有系统自带的库实现的。由此我们可以看出,那些给逻辑复杂,容易出错的代码写单测边际收益更大。并不是说 ViewModel 的单测没有任何意义,而是如果我们只有给一个部分写单测,我们应该写给网络代码。
薛定谔的单元
不知道你有没有仔细想过单元测试中的单元到底代表什么,是变量,方法,Class,还是模块?答案是都是,也都不是。你可能在想,怎么会有如此量子的概念?这是因为单元测试中的单元在被定义之前可以是上边说的任何一种存在,直到你定义了它才会有具体的意义,我愿称之为薛定谔的单元。
测试粒度
在这里我就想引入一个概念,叫测试粒度。上边说了,对于单元我们可以选择它是变量,方法,Class,甚至是模块。这个对于单元的选择就是粒度,选择越大的区块意味着越粗的粒度,比如 Class 的粒度就比方法的粒度要粗。
粒度的囚徒困境
囚徒困境是指个体的理性选择往往导致群体的非理性。放在这里就是,细粒度的最大化的测试往往导致更粗力度的测试的困难。假设我们在方法的维度做了最大化的测试(给 private 的方法也做了测试),对于 Class 维度来说,测试代码和代码结构的耦合度太高,这个带来的问题就是,每当你给 Class 做重构的时候(重构意味着改变代码的内部结构而不改变其对外的行为),有很多单测就会挂掉。这意味着你又要重新写这些单测,这样的话单测就失去了你重构守护者的身份,反而成为了重构的负担。更严重的是,你会越来越反感单测,最后选择放弃。
选择合适的测试粒度
想解决上边所说的困境,第一步就是要选择一个合适的测试粒度,在这里我推荐选择 Class 作为单元的测试粒度,因为这样对于维护代码和重构都比较友好。
在定下了合适的测试粒度之后,我们就需要再思考一个问题,什么样的代码需要写单测?你可能会问了,这个问题不是在上一篇 A song of TDD and BUG - 主歌 中讨论过了吗?但在这里我们想讨论的是给哪些代码写单测更高效。这就有点像法律和道德之前的关系,之前讨论的规则是基本法,是你不能逾越的红线,弄不好是要坐牢的。但是现在讨论的更像道德,你可以选择不去遵循,但是遵循了可以让你谈笑风生。
这里要遵循的的原则就是要测试单元可观测的行为,你需要这样想:我的输入时 x 和 y,输出是不是 z?而不是:我的输入是 x 和 y,是不是调用了 A 类的方法 f,然后返回方法的返回值 z。private 方法应该被视为实现细节,如果不是非常需要,我们不应该主动去测试他们。所以我们更需要关注的是 public 的接口,相应的也应该对接口进行测试。比如我的做法就是用 Xcode 生成需要测试 Class 的接口文件,看有哪些输出,然后用不同的输入来测试是否能得到想要的输出。
更高级别的测试
如果我再扩大测试粒度的话,比如把单元变成整个流程甚至整个 App,量变引起质变,这个就超出单元测试的范畴进入集成测试或者是验收测试的范畴了。与之相对应的,测试的成本会上升,效率会下降。那你可能会问了,既然大粒度的测试如集成测试有更高的成本和更低的效率,它们为什么还会存在?
我们在写单测的时候会主动地去移除外部依赖以保证单元测试的单元性,但是外部环境(数据库,文件系统,向其他应用发起网络请求)也是软件系统中非常重要的一部分,所以我们需要编写一些测试可以覆盖到这些依赖。
接下来我们就说一下集成测试:在编写集成测试的时候我们应该尽可能的在本地运行外部依赖。拿 Rainstorm 来举例,如果要做集成测试,我们就需要在本地起一个服务器来充当 DarkSky API 的角色,然后对整个流程进行测试。
测试金字塔
从上边我们知道了测试是分层级的,对于他们之间的关系有一个很好的比喻-测试金字塔。你可能会想,为啥是金字塔,不是长城,不是空中花园?这是因为理想情况下,越低层级的测试的占有率应该越高。如下图(这张图是从网上扒的,就大概表达一下意思,并不是说我们一定要按照图里的测试层级去设计自己的测试):
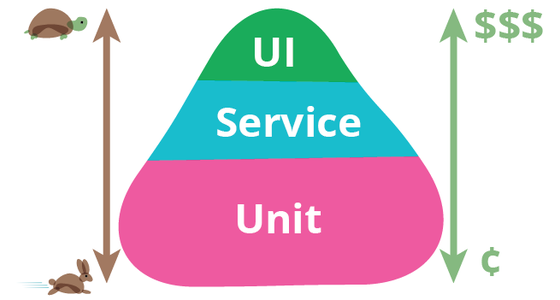
从图中我们也可以看到他想表达的意思就是越高层级的测试效率会下降,成本会上升。
以 Rainstorm 为例,我们可以参考的测试金字塔从低到高可以是:单元测试 -> 集成测试 -> UI 测试 -> 人工测试。不过这个还是要看不同项目的不同需求。
Depth Of Test
这个概念是我在这篇博客 Introducing Depth of Test (DOT) 中看到的,文中借用了摄影中景深(Depth of Field)的概念,定义了 Depth Of Test(测试深度) 为在一次测试中所启动的最近软件原件(software component)到最远软件元件之间的距离。这个软件元件可以代表 Class 或 Function 甚至模块等等。
下边我继续以 Rainstorm 为例说明一下测试深度。在我们对 RootViewModel 做单测的时候,我们想测试是否能通过网络层代码拿到正确的数据,我们的测试时候软件元件的路径是这样的:从 MockLocationService 中拿到位置数据,传递给 MockNetworkService 然后得到输出。由此可见我们的测试深度是 2。现在假设我们用人工的方式来测试,App 的流程是:进入页面后 RootViewController 会初始化 RootViewModel,然后 RootViewModel 通过 LocationManager(底层是 CLLocation) 请求位置,收到位置后由 NetworkManager(底层是 URLSession)再向 DarkSky API 请求天气数据,得到天气数据后通过 RootViewModel 生成 DayViewModel,然后由 DayViewController 来展示天气数据(在得到天气数据之后的数据流动在计算测试深度的时候我们可以暂时忽略)。在上边这次测试中最近的软件元件是 RootViewController 而最远的软件元件是 URLSession,所以测试深度是 6。
有了测试深度这个概念我们就可以发现,其实金字塔从底层到高层其实就是测试深度从浅到深的不同。这也解释了为什么金字塔层级越高的测试效率越低。
金字塔 VS. 冰激凌
前边说了理想状态下的测试层级是金字塔形状的,但是有理想就有苟且,那金字塔的对立面就是另一种模式 - 冰激凌模式,下边两张图就是两种不同模式的对比。
金字塔: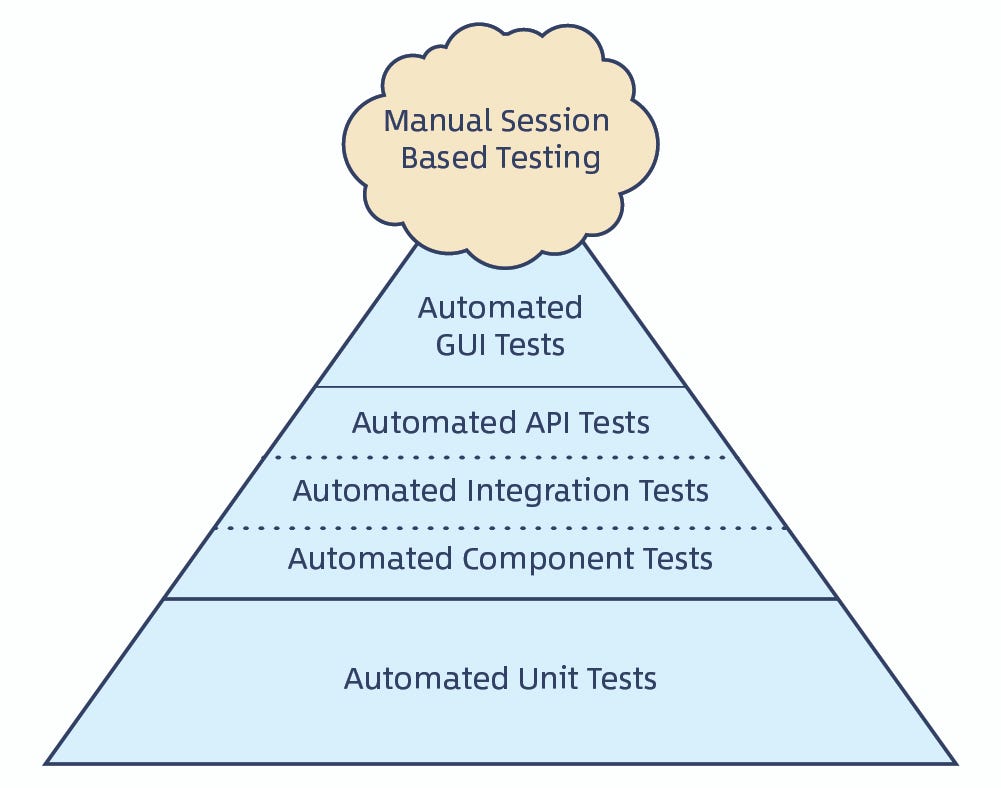
冰淇淋: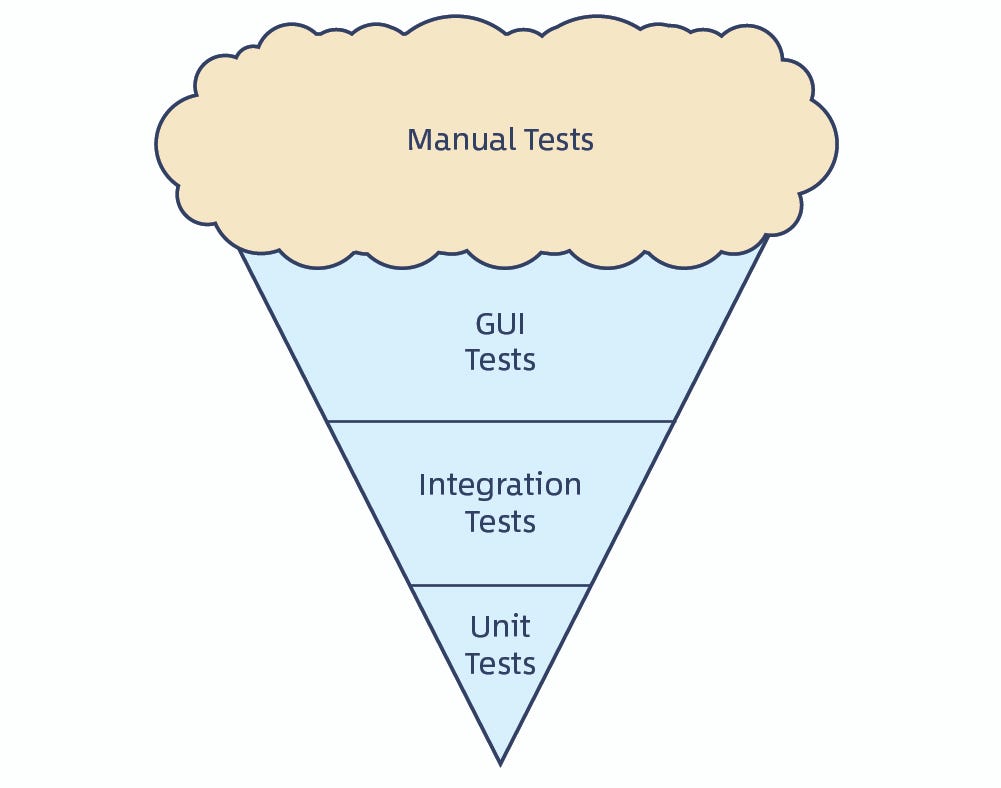
看冰激凌模式眼熟的在评论区刷波 1。
冰激凌模式存在的问题就是平均测试深度过深,相应的测试效率和成本都会比金字塔模式表现得差。
测试下沉原则
如果一个更高层级的测试发现了一个错误,并且底层测试全都通过了,那么你应该写一个低层级测试去覆盖这个错误。
如果在底层测试(单元测试)完全通过的情况下,我们在更高层的测试中(比如 UI 测试或者人工测试)中发现了一个 Bug, 我们应该在更底层补充相应的测试来覆盖这种情况。因为低层级测试让你更容易缩小错误的范围并且有更高的运行效率。
另外需要注意的一点就是,如果底层的测试已经完全能够覆盖之前发现的问题,可以选择在高层的测试中删除这部分测试,这样可以避免重复测试。如果问题评估比较重要,可以保留,因为这样可以增加上线的自信度。
结语
本章粗略总结了一下 TDD 的基本步骤和单元测试之外的几个重要的测试。一个很重要的概念就是测试金字塔,这个是所有测试的基本哲学,在构架你的 FTDD 的时候一定要考虑到。
相关链接
相关链接:
测试金字塔实战
TestPyramid
Introducing the Software Testing Cupcake (Anti-Pattern)
Automated Testing and the Test Pyramid
Introducing Depth of Test (DOT)
